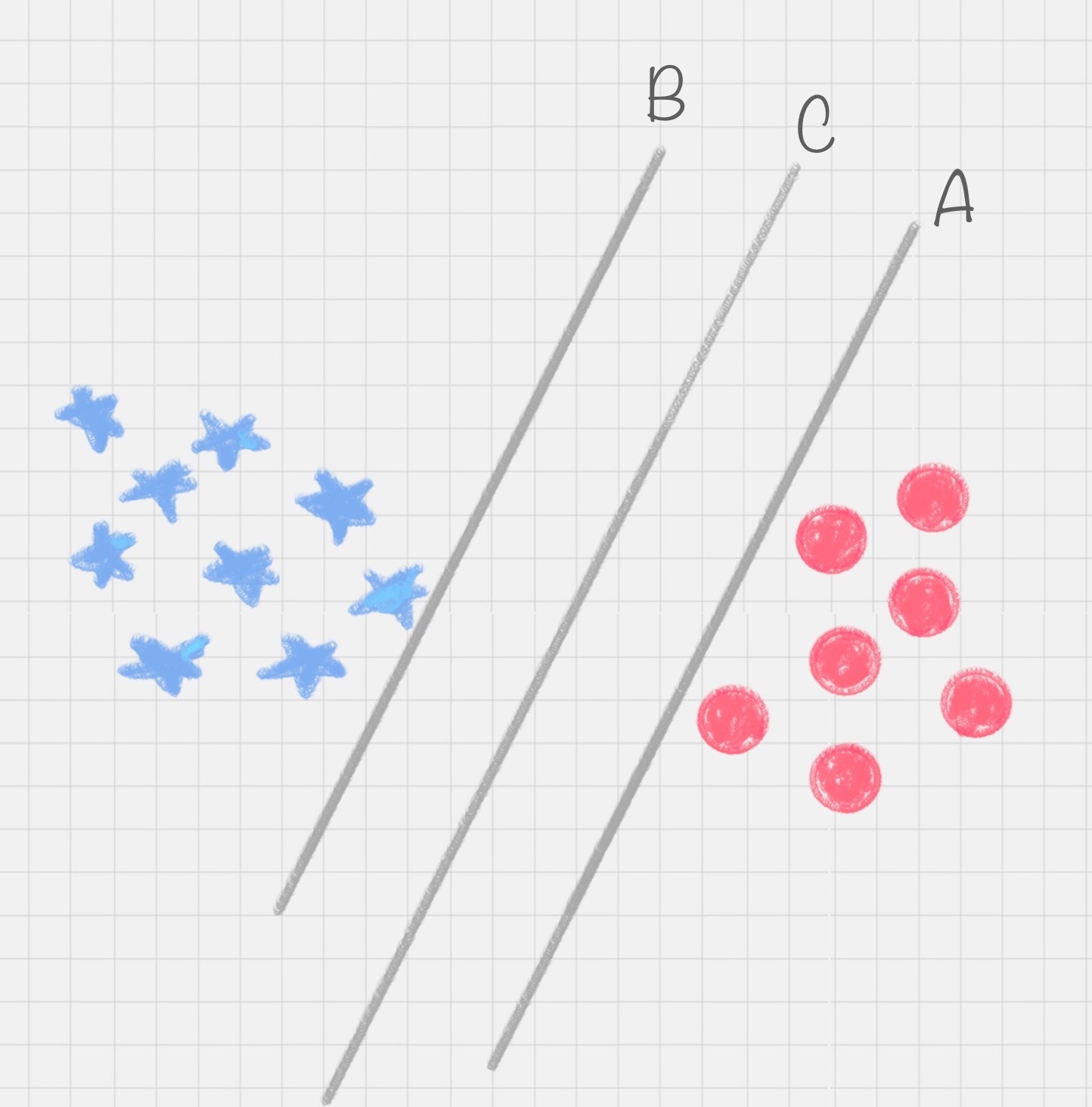
超平面是帮助我们在多维空间中找到分类数据的分类器. 用svn 计算就是帮我们找到超平面的过程
比如右图所示的直线 A、直线 B 和直线 C,究竟哪种才是更好的划分呢?
很明显图中的直线 B 更靠近蓝色球,但是在真实环境下,球再多一些的话,蓝色球可能就被划分到了直线 B 的右侧,被认为是红色球。同样直线 A 更靠近红色球,在真实环境下,如果红色球再多一些,也可能会被误认为是蓝色球。所以相比于直线 A 和直线 B,直线 C 的划分更优,因为它的鲁棒性更强。
那怎样才能寻找到直线 C 这个更优的答案呢?这里,我们引入一个 SVM 特有的概念:分类间隔。
实际上,我们的分类环境不是在二维平面中的,而是在多维空间中,这样直线 C 就变成了决策面 C。
在保证决策面不变,且分类不产生错误的情况下,我们可以移动决策面 C,直到产生两个极限的位置:如图中的决策面 A 和决策面 B。极限的位置是指,如果越过了这个位置,就会产生分类错误。这样的话,两个极限位置 A 和 B 之间的分界线 C 就是最优决策面。极限位置到最优决策面 C 之间的距离,就是“分类间隔”,英文叫做 margin。
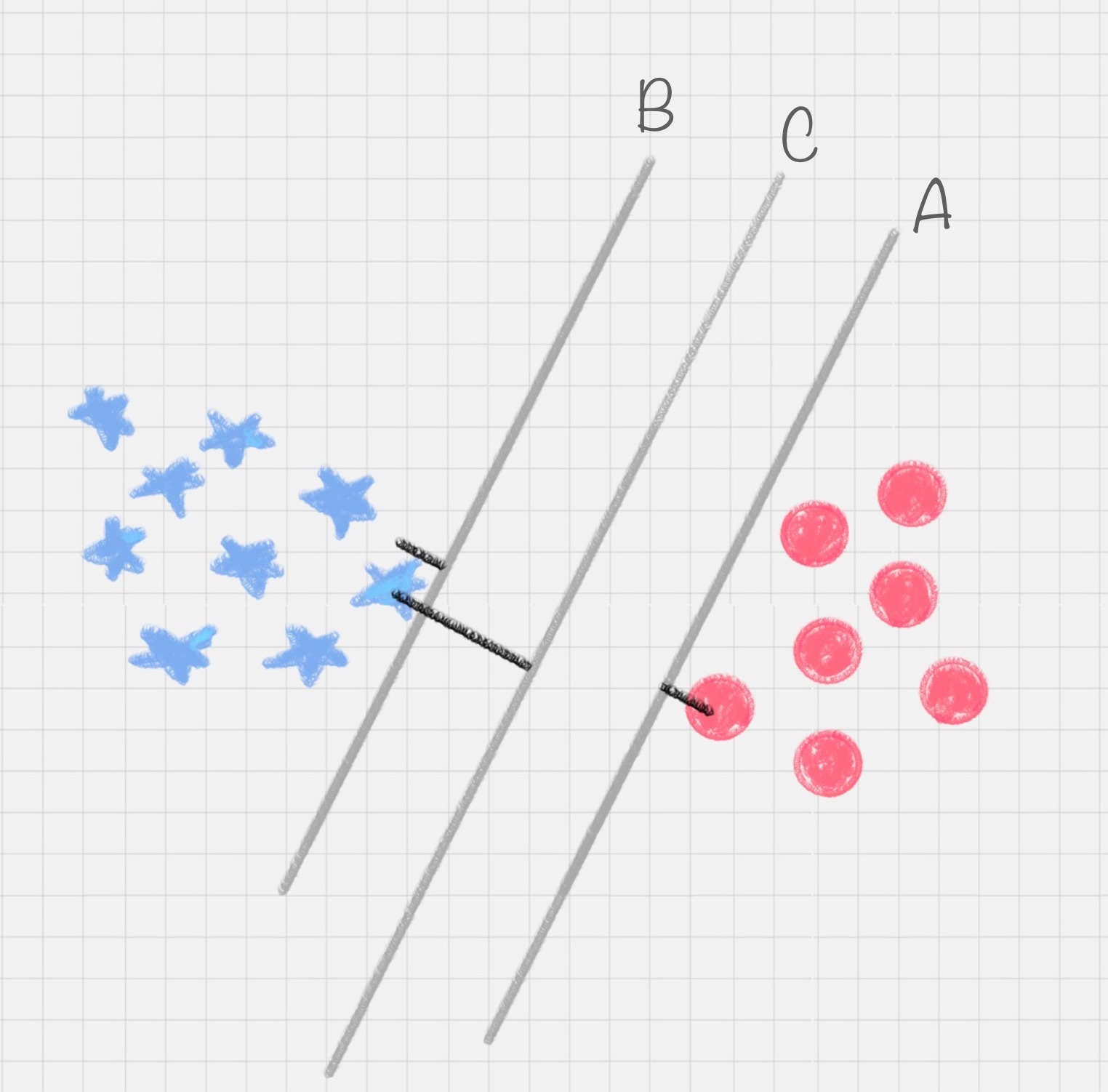
如果我们转动这个最优决策面,你会发现可能存在多个最优决策面,它们都能把数据集正确分开,这些最优决策面的分类间隔可能是不同的,而那个拥有“最大间隔”(max margin)的决策面就是 SVM 要找的最优解。
点到超平面的距离公式
在上面这个例子中,如果我们把红蓝两种颜色的球放到一个三维空间里,你发现决策面就变成了一个平面。这里我们可以用线性函数来表示,如果在一维空间里就表示一个点,在二维空间里表示一条直线,在三维空间中代表一个平面,当然空间维数还可以更多,这样我们给这个线性函数起个名称叫做“超平面”。超平面的数学表达可以写成:
$$ g(x)=w^Tx+b, 其中w,x\in R^n $$
在这个公式里,w、x 是 n 维空间里的向量,其中 x 是函数变量;w 是法向量。法向量这里指的是垂直于平面的直线所表示的向量,它决定了超平面的方向。
SVM 就是帮我们找到一个超平面,这个超平面能将不同的样本划分开,同时使得样本集中的点到这个分类超平面的最小距离(即分类间隔)最大化。
在这个过程中,支持向量就是离分类超平面最近的样本点,实际上如果确定了支持向量也就确定了这个超平面。所以支持向量决定了分类间隔到底是多少,而在最大间隔以外的样本点,其实对分类都没有意义。
所以说, SVM 就是求解最大分类间隔的过程,我们还需要对分类间隔的大小进行定义。
首先,我们定义某类样本集到超平面的距离是这个样本集合内的样本到超平面的最短距离。我们用 di 代表点 xi 到超平面 wxi+b=0 的欧氏距离。因此我们要求 di 的最小值,用它来代表这个样本到超平面的最短距离。di 可以用公式计算得出:
$$ d_i=\frac{wx_i+b}{||w||} $$
其中||w||为超平面的范数.